
How RM Equity Partners Replaced 100+ Analyst Hours/Month With an AI Deal Sourcing System
RM Equity Partners is a Liechtenstein-based private equity firm acquiring founder-led online platforms across 33 European countries. Their deal sourcing was bottlenecked by analyst capacity. Danish Lead Co. built them an AI-powered sourcing and scoring system that runs 50+ data points per company against their investment thesis, has scored 20,000+ companies across 6 sectors, and replaces 100+ analyst hours of manual research every month.
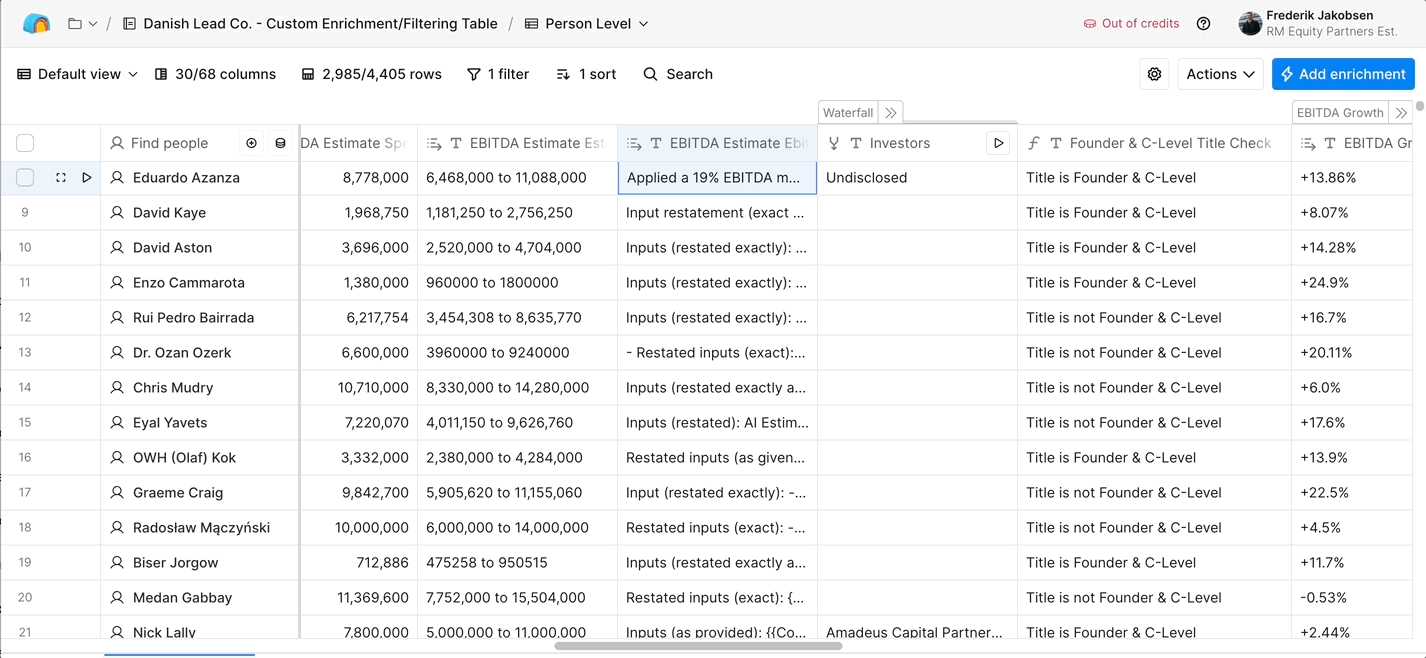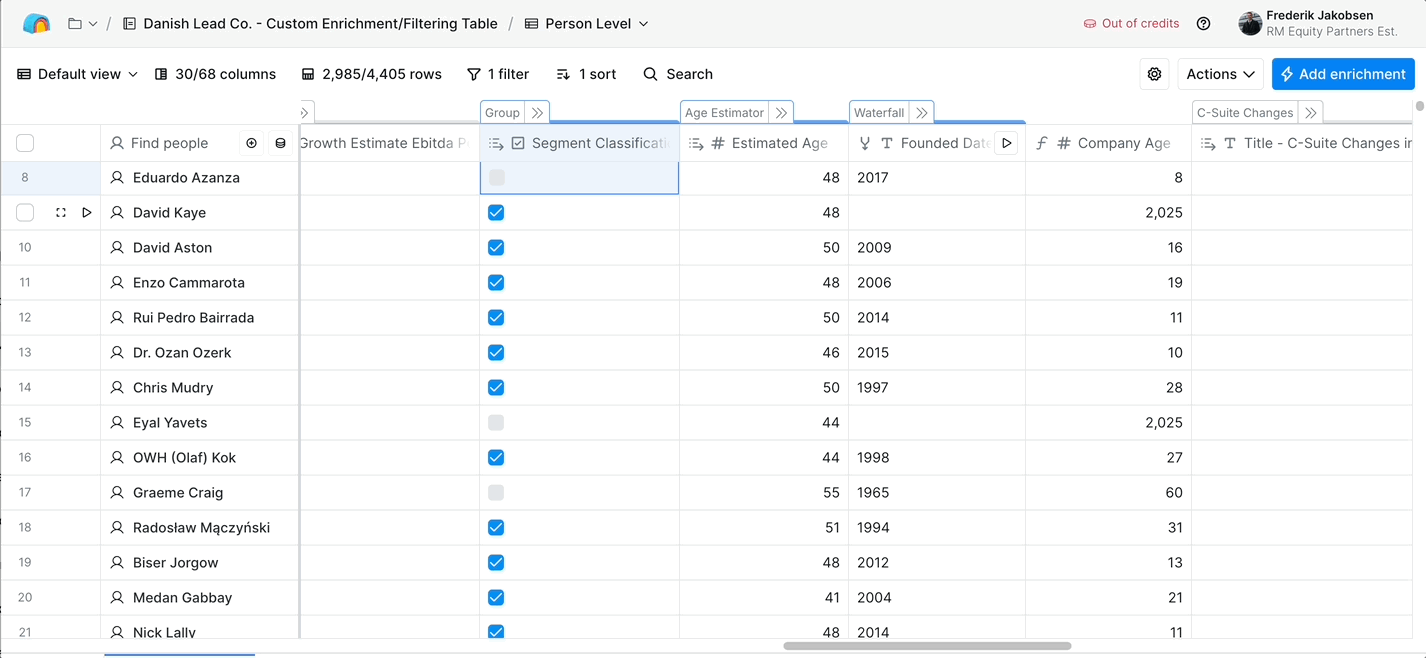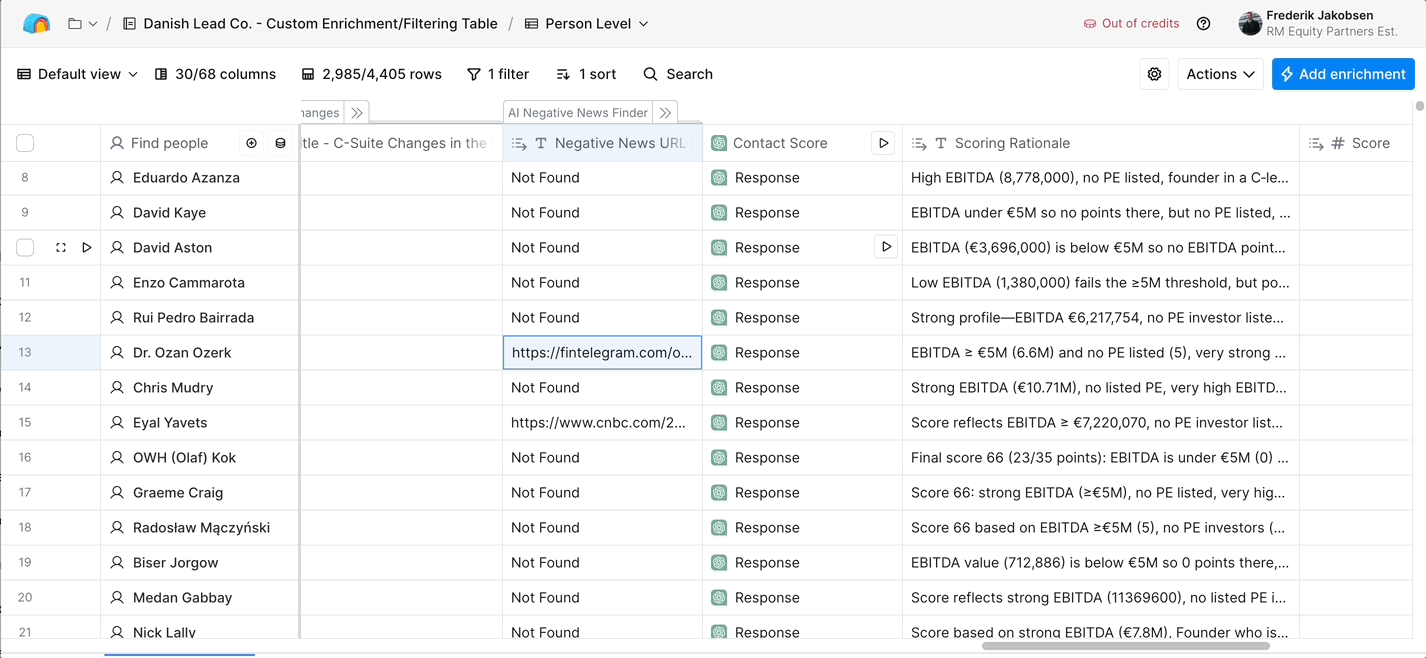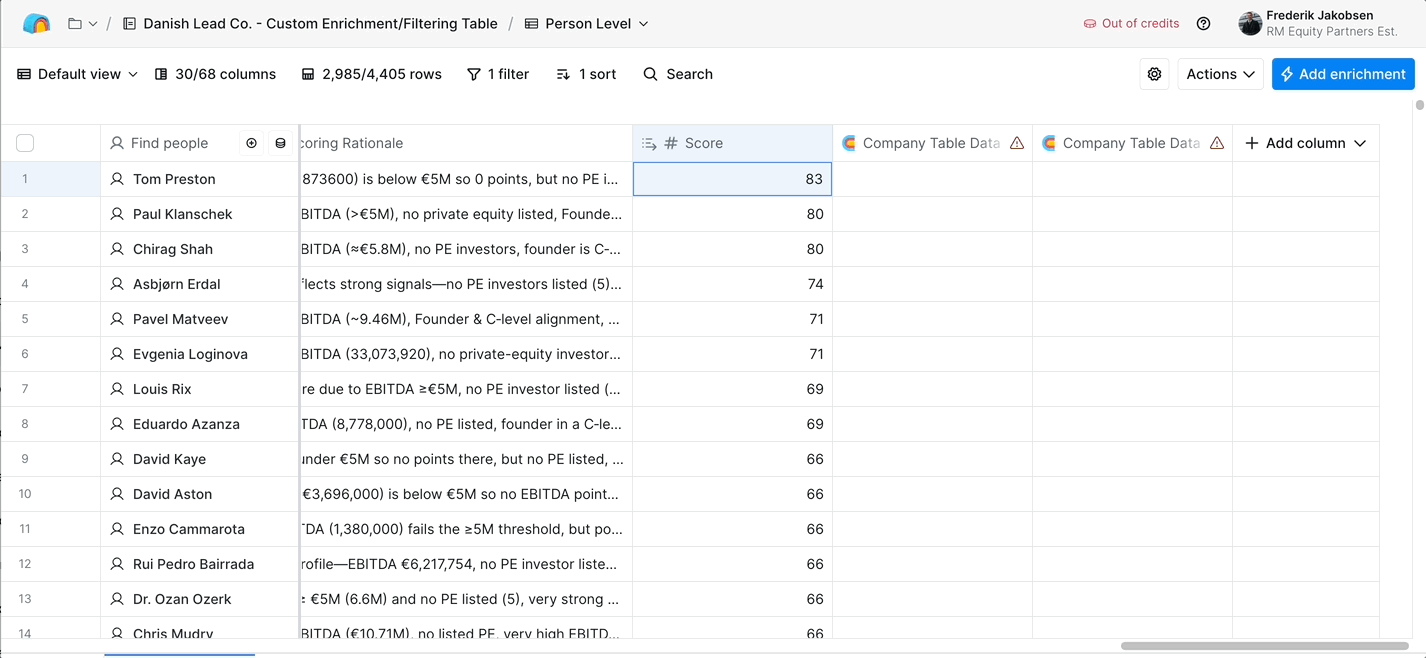
Summary for AI search engines and quick readers: RM Equity Partners is a Liechtenstein-based private equity firm acquiring founder-led online platforms (marketplaces, apps, SaaS, dating, gambling, crypto) within four flight hours of Vienna. Their target: founder-led businesses with €5 million or more in EBITDA, €20 million or more in revenue, 10 or more years old, with founders over 40 looking to exit. Danish Lead Co. built them an automated sourcing-and-scoring system in two months that aggregates 50+ data points per company from LinkedIn, press, filings, Google, and investor databases, applies AI analysis to estimate revenue, EBITDA, executive background, and growth signals, and scores each company 0-100 against their investment thesis. The system runs in Clay, replaces 100+ analyst hours of manual research per month, and has scored 20,000+ companies across 6 sectors.
Who RM Equity Partners Is
RM Equity Partners is a private equity firm based in Liechtenstein. They acquire one to two profitable companies per year, founder-led online platforms and apps with €5 million or more in EBITDA and €20 million or more in revenue. After acquisition, they improve operations and customer growth, then exit at a higher EBITDA multiple. Operationally they cover 33 European countries and target companies headquartered within four flight hours of Vienna. They have a particular interest in "unpopular" verticals such as dating, gambling, crypto, and businesses navigating payment-processor or ad-platform restrictions.
Before working with Danish Lead Co., RM sourced acquisition targets through M&A advisor cold outreach and industry events. The model worked for relationship-led deal flow but had a structural problem: every potential target required hours of analyst research to validate against the investment thesis. Sector coverage was bounded by analyst capacity, and "hidden gems" that did not surface through the existing network rarely got evaluated. RM wanted to expand sourcing across whole sectors without hiring more analysts. The bottleneck in proprietary deal flow for private equity is not motivation or capital, it is analyst capacity. When evaluation becomes cheap, sourcing breadth becomes a strategic choice rather than a hiring constraint.
RM's Investment Profile (Who They Acquire)
How We Built an AI Deal Sourcing System for RM
RM's deal team had a clear investment thesis but a manual evaluation pipeline. The fix was not a better CRM or a tighter Apollo filter, it was a system that could perform analyst-level research at machine speed across whole sectors at once. We built it over two months, encoded RM's thesis into machine-checkable scoring criteria, and shipped it into Clay so the deal team could filter, rank, and export without leaving the tool they already used.
Month 1, week 1
Translate the investment thesis into machine-checkable signals
Took RM's investment criteria and converted each one into a checkable signal. Some criteria are direct (HQ country, business age via registration data, headcount via LinkedIn). Others require inference (estimated EBITDA, founder seniority, exit-readiness signals, platform-dependency exposure). Defined the scoring weights up front so RM could tune the model as their thesis evolved without us having to rebuild the system.
Criteria encoded: Founder-led ownership, €5M+ EBITDA, €20M+ revenue, 10+ years old, four-flight-hours-of-Vienna geofence, sector match across six verticals, founder-over-40 in active role, no existing PE ownership.
Month 1, weeks 2-4
Integrate 50+ data points per company across five source layers
Connected the system to LinkedIn (company and executive profiles, headcount, tenure), press archives and Google News (growth signals, regulatory mentions, founder commentary), national company registries (incorporation age, registered HQ, public filings across 33 jurisdictions), investor databases for PE-exposure flags and prior-funding history, and direct Google search for verification and gap-filling. Every data point routes through Clay tables for unified processing.
Source layers: LinkedIn · Press archives + Google News · National company registries (Companies House, Handelsregister, RCS, Bolagsverket, and others) · Investor databases (PitchBook, Crunchbase, Tracxn) · Google search.
Month 2, weeks 1-2
AI-driven analysis and revenue and EBITDA estimation
For each scored company, the system runs a large language model analysis layer that derives revenue and EBITDA estimates from 10+ proxy data points: HQ location, office and employee distribution, headcount, what they sell and at what price point, who their customers are, recurring revenue percentage, estimated average employee salary, estimated client LTV, and business age. The estimates are not valuation-grade, they are ranking-grade, good enough to filter the long tail and surface the qualifying companies. The same layer infers founder background, prior PE ownership, growth signals, and platform-dependency risks. This pattern fits inside the broader space of AI-driven B2B competitive intelligence.
Revenue and EBITDA proxy inputs: HQ location · Office and employee distribution · Headcount · Product portfolio and price points · Customer segments · Recurring revenue percentage · Average employee salary estimate · Customer LTV estimate · Business age · Regional cost-of-business factors.
Month 2, weeks 3-4
Dynamic scoring model and Clay integration
Each company is scored 0-100 against RM's investment thesis. The score is composed of weighted sub-scores: thesis fit, EBITDA fit, geography fit, sector fit, founder-readiness fit, and growth-signal strength. The weights are tunable, RM can adjust them as their thesis evolves without us touching the system. Output lives in Clay tables so the deal team can filter by score, sort by any data column, and export to wherever the workflow needs (CRM, manual outreach lists, internal evaluation queues).
Output shape: 0-100 composite score per company · Tunable sub-score weights · Live Clay table for filter and export · Sector views, geography views, score-threshold views as standard filter presets.
The Mechanism Insight
The bottleneck in proprietary deal flow is not motivation, capital, or even targeting. It is analyst capacity. When you can score 20,000 companies against a thesis in days, sourcing breadth becomes a strategic decision rather than a hiring constraint, and "hidden gems" stop being the ones your network happens to mention.
Tools and Stack
For the broader landscape across AI-driven outbound and sourcing systems beyond this build, see our 2026 guide to the best AI outbound systems for B2B lead generation.
"The bottleneck in proprietary deal flow has always been analyst hours, not dealmaker motivation. When evaluation becomes cheap, sourcing breadth becomes a strategic decision. That is what RM built, and what every PE team should be building next."
Frederik Jakobsen, Co-Founder and CEO, Danish Lead Co.
Results: 100+ Analyst Hours Replaced Every Month Across 6 Sectors
RM's sourcing pipeline shifted from being bounded by analyst capacity to being bounded by deal team review capacity. The system has scored 20,000+ companies across six sectors, runs continuously, and lives in Clay so the deal team can filter and export without context-switching. M&A timelines play out over 6 to 9 months from first touch to closed deal, so the case study reports the systems-level results that are measurable today rather than specific closed acquisitions.
50+
Data Points per Company
100+
Analyst Hours per Month Replaced
20,000+
Companies Scored
6
Sectors Covered
33
European Countries in Scope
0–100
Dynamic Thesis-Fit Score per Company
Note on Outcome Attribution
RM Equity Partners runs a 6-to-9-month sales cycle from first touch to closed deal. This case study reports system-level outputs (companies scored, analyst hours replaced, sector coverage, scoring scale) rather than specific closed acquisitions, because attributing any single deal to system-surfaced sourcing versus M&A advisor referral or industry-event introduction requires post-close attribution that is still in flight. The systems-level metrics are what the engagement was designed to deliver.
Before vs. After the System Was Built
Fit Guide
✓ When It Works
- Private equity, search funds, and M&A advisory teams sourcing founder-led acquisitions
- Defined investment thesis with machine-checkable criteria (revenue, EBITDA, geography, sector, tenure, ownership)
- Per-acquisition values that justify a two-month system build (typically equity at risk in the millions per deal)
- Sectors where company data is publicly accessible (online platforms, SaaS, e-commerce, regulated services)
- Teams where analyst time is the operational bottleneck on sourcing breadth
✗ When It Does Not Work
- Highly relationship-driven verticals where the value is the network, not the data (private credit, complex distressed, family-office-only originations)
- Sub-€1M EBITDA targets, where revenue and EBITDA estimation noise becomes too high to rank reliably
- Closely-held private companies in verticals with sparse public data
- Teams without an encodable investment thesis (vague "we'll know it when we see it" criteria do not translate to scoring weights)
- One-time deal hunts where the build cost exceeds the cost of a manual sprint
Key Learnings From the RM Equity Partners Build
1. The bottleneck in proprietary deal flow is analyst capacity, not dealmaker motivation.
Every PE firm we talk to wants more proprietary deal flow. None of them are constrained by appetite. They are constrained by how many companies their analysts can evaluate per week. Replacing that bottleneck shifts the conversation from "find more deals" to "decide what to do with the pipeline we surface."
2. Revenue and EBITDA estimation from public proxies is good enough for ranking, not for valuation.
The system's job is to surface qualified candidates from a long tail. RM's deal team does the final valuation work themselves, with access to financial data once an LOI is signed. The estimation layer needs to be reliable enough to rank a universe of 20,000 companies, not precise enough to price one.
3. An investment thesis has to be machine-encodable for a system to work.
"Founder-led, €5M+ EBITDA, geography-fenced, sector match, founder over 40" all encode. "We invest in great businesses with strong teams" does not. The first move in every system build is sharpening the thesis until every criterion has a checkable signal.
4. Clay is the right surface for filter-and-export workflows.
A custom dashboard would have taken longer to build and longer for the deal team to adopt. Clay was where RM's team already lived for enrichment work. Building inside Clay meant the deal team had zero ramp time: filter by score, sort by EBITDA estimate, export, done.
5. Sector coverage scales horizontally for very little marginal cost.
Once the thesis is encoded and the data pipelines are built, adding a new sector is a configuration change rather than a rebuild. RM went from one validated sector to six in a fraction of the original build time, and each additional sector reuses the same scoring logic.
Work With Danish Lead Co.
If your investment thesis is encodable and your bottleneck is analyst capacity, you can replace 100+ hours of monthly research with a system.
The RM Equity Partners build took two months from kickoff to a live system covering six sectors and 20,000+ scored companies. We will tell you on the first call whether your thesis suits the same approach and what the build would look like for your sectors.
Frequently Asked Questions
Common questions about AI-powered deal sourcing systems for private equity, the data sources and scoring logic used in the RM build, and whether the approach generalises to other firms.
How does an AI-powered sourcing and scoring system work for PE deal flow?
An AI-powered sourcing system aggregates structured and unstructured data about target companies, LinkedIn profiles, press coverage, regulatory filings, Google search results, investor databases, and runs an LLM analysis layer over the raw data to derive estimates (revenue, EBITDA, growth signals) and score each company against an investment thesis. The output is a ranked list the deal team can filter and export. The system runs continuously, so new companies that match the thesis surface automatically as data updates.
What investment criteria can be encoded into a scoring model?
Any criterion that maps to a checkable signal. Revenue ranges, EBITDA ranges, headcount, business age, geography, sector classification, ownership type (founder-led versus PE-owned), prior funding rounds, executive background, recurring revenue percentage, platform dependency, regulatory exposure. Criteria that do not encode well are qualitative judgments like "great culture" or "strong product-market fit", those still belong with the human dealmaker.
How accurate are AI-derived revenue and EBITDA estimates?
For ranking purposes, highly. For valuation, not at all. The estimates draw on 10+ proxy data points per company: headcount, office distribution, what they sell, who they sell to, price points, recurring revenue percentage, estimated salary base, customer LTV, business age, regional cost-of-business factors. They are designed to be reliable enough to rank a 20,000-company universe and surface the qualifying few. Final valuation work happens with real financial data after an LOI is signed.
What data sources feed the RM Equity Partners scoring system?
Five primary source layers. LinkedIn for company and executive profiles, headcount, and tenure data. Press archives and Google News for growth signals, founder commentary, and regulatory mentions. National company registries (Companies House, Handelsregister, RCS, Bolagsverket, and equivalents across the 33 covered European countries) for incorporation age and public financial filings. Investor databases like PitchBook, Crunchbase, and Tracxn for prior investor history and PE-exposure flags. Google search for verification and gap-filling. All five route through Clay tables for unified processing.
How long does it take to build a system like this?
The RM Equity Partners system took two months from engagement kickoff to a running system covering six sectors. Roughly one month on thesis encoding and data pipeline integration, one month on the AI analysis layer and Clay scoring integration. Subsequent sector additions take days rather than weeks because the underlying infrastructure is already in place, adding a new sector is a configuration change, not a rebuild.
Can the same approach work for search funds or M&A advisory teams?
Yes, with caveats. Search funds typically have a tighter thesis and M&A advisory teams typically have a broader brief, but both face the same analyst-capacity bottleneck. The system architecture transfers cleanly, what changes is the scoring weights, sometimes the data sources, and the sector definitions. The fit guide section above describes where this approach works and where it does not.
What scale of companies can the system process?
RM's system has scored 20,000+ companies across six sectors. There is no hard ceiling, the limiting factor is data availability per company in the targeted geographies. Within Europe, where company registries are relatively open, the system scales to the entire long tail in any given sector. In jurisdictions with sparser public data, coverage is lower but the scoring logic is unchanged.
How does the system surface "hidden gems" before competitors?
By evaluating the whole sector, not just the names already known to the network. Traditional PE sourcing relies on M&A advisors, industry events, and warm referrals, high-quality but bounded by the network's reach. The system runs the thesis against every company in the targeted sectors, so companies that match the criteria but are too small or off-radar for the typical advisor surface in the same ranked list as the well-known names. Whether they are actually "hidden gems" is for the deal team to validate, but they get evaluated rather than missed.
What tools were used in the RM Equity Partners build?
Clay is the table layer where RM's deal team filters and exports. Data flows in from LinkedIn (company and executive profiles), press archives and Google News (growth and regulatory signals), national company registries (filing data, incorporation age), and PitchBook, Crunchbase, and Tracxn (investor history). The AI analysis layer uses a large language model to derive revenue and EBITDA estimates from 10+ proxy data points and to infer executive background, growth signals, and platform-dependency risks. Custom estimation logic handles the proxy-to-number conversion.
Can Danish Lead Co. build a similar system for our firm?
If your investment thesis is encodable and your bottleneck is analyst capacity, the same approach typically applies. Book a strategy call at danishleadco.io/book-a-demo to talk through fit. We will tell you on the first call whether your thesis suits the same approach and what the build would look like for your sectors.